Premier league prediction¶
Original code from https://github.com/RudrakshTuwani/Football-Data-Analysis-and-Prediction
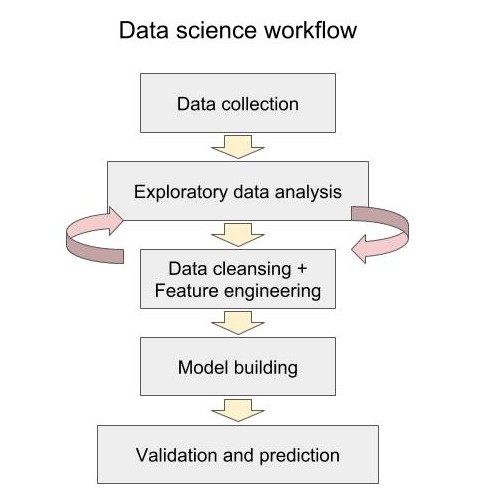
1. Data collection¶
Also from https://github.com/RudrakshTuwani/Football-Data-Analysis-and-Prediction
Typically the most difficult task¶
2. Data cleansing and feature engineering¶
In [43]:
# Import the necessary libraries.
import pandas as pd
import numpy as np
from datetime import datetime as dt
# Import local methods
from featureEng import *
# Not show warnings
import warnings
warnings.simplefilter(action='ignore')
In [44]:
# Import raw data
dataset_loc = '/home/chatdanai/Football-Data-Analysis-and-Prediction-master/Datasets/'
raw_data_1 = pd.read_csv(dataset_loc + '2000-01.csv')
# Parse data as time
raw_data_1.Date = raw_data_1.Date.apply(parse_date)
raw_data_1.head()
Out[44]:
In [45]:
#Gets all the statistics related to gameplay
columns_req = ['Date','HomeTeam','AwayTeam','FTHG','FTAG','FTR']
playing_stat = raw_data_1[columns_req]
In [46]:
playing_stat.head()
Out[46]:
In [47]:
# Gets the goals scored agg arranged by teams and matchweek
playing_stat = get_gss(playing_stat)
In [48]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[48]:
In [49]:
# Gets teams' points before the match
playing_stat = get_agg_points(playing_stat)
In [50]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[50]:
In [51]:
# Gets forms of the teams
playing_stat = add_form_df(playing_stat)
In [52]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].tail()
Out[52]:
In [53]:
# Gets matchweek
playing_stat = get_mw(playing_stat)
In [54]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[54]:
In [55]:
# Gets last season standing
Standings = pd.read_csv(dataset_loc + "EPLStandings.csv")
Standings.set_index(['Team'], inplace=True)
Standings = Standings.fillna(18)
playing_stat = get_last(playing_stat, Standings, 0)
In [56]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[56]:
In [57]:
# Gets the form points.
playing_stat['HTFormPtsStr'] = playing_stat['HM1'] + playing_stat['HM2'] + playing_stat['HM3'] + playing_stat['HM4'] + playing_stat['HM5']
playing_stat['ATFormPtsStr'] = playing_stat['AM1'] + playing_stat['AM2'] + playing_stat['AM3'] + playing_stat['AM4'] + playing_stat['AM5']
playing_stat['HTFormPts'] = playing_stat['HTFormPtsStr'].apply(get_form_points)
playing_stat['ATFormPts'] = playing_stat['ATFormPtsStr'].apply(get_form_points)
In [58]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[58]:
In [59]:
# Get Goal Difference
playing_stat['HTGD'] = playing_stat['HTGS'] - playing_stat['HTGC']
playing_stat['ATGD'] = playing_stat['ATGS'] - playing_stat['ATGC']
# Diff in points
playing_stat['DiffPts'] = playing_stat['HTP'] - playing_stat['ATP']
playing_stat['DiffFormPts'] = playing_stat['HTFormPts'] - playing_stat['ATFormPts']
# Diff in last year positions
playing_stat['DiffLP'] = playing_stat['HomeTeamLP'] - playing_stat['AwayTeamLP']
In [60]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[60]:
In [61]:
# Scale DiffPts , DiffFormPts, HTGD, ATGD by Matchweek.
cols = ['HTGD','ATGD','DiffPts','DiffFormPts','HTP','ATP']
playing_stat.MW = playing_stat.MW.astype(float)
for col in cols:
playing_stat[col] = playing_stat[col] / playing_stat.MW
In [62]:
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[62]:
In [63]:
# Simplifies the problem to only 'H' vs 'NH'
playing_stat['FTR'] = playing_stat.FTR.apply(only_hw)
playing_stat[(playing_stat[['HomeTeam','AwayTeam']]=='Liverpool').any(axis=1)].head()
Out[63]:
In [64]:
import matplotlib.pyplot as plt
%matplotlib inline
In [65]:
playing_stat.columns
Out[65]:
In [66]:
# Read data and drop redundant column.
usecols = ['Date', 'MW', 'HomeTeam', 'AwayTeam', 'FTHG', 'FTAG', 'FTR', 'HTP', 'ATP',
'HM1', 'HM2', 'HM3', 'AM1', 'AM2', 'AM3',
'HTGD', 'ATGD', 'DiffPts', 'DiffFormPts', 'DiffLP']
data = pd.read_csv(dataset_loc + 'final_dataset.csv', usecols=usecols)
data.sample(10)
Out[66]:
In [67]:
# Remove first 3 matchweeks
data = data[data.MW > 3]
columns_to_drop = ['Date', 'HomeTeam', 'AwayTeam', 'FTHG', 'FTAG', 'MW', 'DiffPts']
data.drop(columns=columns_to_drop, inplace=True)
data.sample(10)
Out[67]:
In [68]:
# Total number of matches
n_matches = data.shape[0]
# Calculate number of features.
n_features = data.shape[1] - 1
# Calculate matches won by home team.
n_homewins = len(data[data.FTR == 'H'])
# Calculate win rate for home team.
win_rate = (float(n_homewins) / (n_matches)) * 100
# Print the results
print("Total number of matches: {}".format(n_matches))
print("Number of features: {}".format(n_features))
print("Number of matches won by home team: {}".format(n_homewins))
print("Home team win rate: {:.2f}%".format(win_rate))
print("Home team not win rate: {:.2f}%".format(100-win_rate))
# Visualising basic info
data.groupby('FTR').count()['HTP'].plot.bar(figsize=(8,4), fontsize=16, alpha=0.5)
plt.xlabel('Full time result', fontsize=16)
plt.show()

In [69]:
# Available columns to explore
data.columns
Out[69]:
In [71]:
# Check some histogram
col = 'HTGD'
col = 'DiffFormPts'
bins = 100
data[data.FTR=='H'][col].hist(bins=bins, alpha=0.5, figsize=(10,6), label='Home won')
data[data.FTR=='NH'][col].hist(bins=bins, alpha=0.5, label='Home not won')
plt.title(col + ' histogram', fontsize=18)
plt.legend()
plt.show()

In [72]:
# Visualising distribution of data
from pandas.plotting import scatter_matrix
# col_list = ['HTGD','ATGD','HTP','ATP','DiffFormPts','DiffLP']
col_list = ['HTGD','HTP','DiffFormPts']
scatter_matrix(data[col_list], diagonal='hist',
hist_kwds={'bins':20, 'edgecolor':'white', 'color':'green', 'alpha':0.3}, figsize=(10,10))
plt.show()

Spending time on exploratory data analysis is important to gain insights¶
4. Model building¶
What kind of prediction? Regression vs Classification?¶
In [73]:
data.head()
Out[73]:
In [74]:
# Separate into feature set and target variable
X_all = data.drop(['FTR'],1)
y_all = data['FTR']
In [75]:
y_all = y_all.apply(lambda x: 1 if x=='H' else 0)
y_all.head()
Out[75]:
Features = 'independent' varibles = regressors¶
In [76]:
X_all.head()
Out[76]:
In [77]:
# one-hot encoding
X_all = pd.get_dummies(X_all, columns=['HM1', 'HM2', 'HM3', 'AM1', 'AM2', 'AM3'])
In [78]:
X_all.head()
Out[78]:
In [79]:
from sklearn.model_selection import train_test_split
# Shuffle and split the dataset into training and testing set.
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size = 0.3, stratify = y_all)
In [80]:
from sklearn.linear_model import LogisticRegression
# from sklearn.ensemble import RandomForestClassifier
# from sklearn.svm import SVC


In [81]:
logReg = LogisticRegression()
logReg.fit(X_train, y_train)
y_train_pred = logReg.predict(X_train)
y_test_pred = logReg.predict(X_test)
In [82]:
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
import seaborn as sns
In [83]:
print("Home team win rate: {:.2f}%".format(win_rate))
print("Home team not win rate: {:.2f}%".format(100-win_rate))
print('================ TRAIN SCORE ================')
confusion_train = pd.DataFrame(confusion_matrix(y_train, y_train_pred))
print(classification_report(y_train, y_train_pred))
plt.figure(figsize = (5,5))
sns.heatmap(confusion_train, annot=True, cmap=plt.cm.Blues, cbar=False, fmt='d')
plt.ylabel('true label', fontsize=18)
plt.xlabel('prediction', fontsize=18)
plt.show()
print('================ TEST SCORE ================')
confusion_test = pd.DataFrame(confusion_matrix(y_test, y_test_pred))
print(classification_report(y_test, y_test_pred))
plt.figure(figsize = (5,5))
sns.heatmap(confusion_test, annot=True, cmap=plt.cm.Blues, cbar=False, fmt='d')
plt.ylabel('true label', fontsize=18)
plt.xlabel('prediction', fontsize=18)
plt.show()


Ready to bet?¶
In [84]:
predictions = pd.DataFrame(np.column_stack([y_test.values, y_test_pred]), columns=['Actual', 'Prediction'], index=y_test.index)
predictions.head(10)
Out[84]:
Map the predictions back¶
In [85]:
# Check back
usecols = ['Date', 'MW', 'HomeTeam', 'AwayTeam']
data = pd.read_csv(dataset_loc + 'final_dataset.csv', usecols=usecols)
mapped_predictions = data.join(predictions, how='right')
mapped_predictions.head(10)
Out[85]: